mirror of
https://github.com/krahets/LeetCode-Book.git
synced 2026-01-12 00:19:02 +08:00
6.5 KiB
Executable File
6.5 KiB
Executable File
解题思路:
本题考察 哈希表 的使用,本文介绍 哈希表 和 有序哈希表 两种解法。其中,在字符串长度较大、重复字符很多时,“有序哈希表” 解法理论上效率更高。
方法一:哈希表
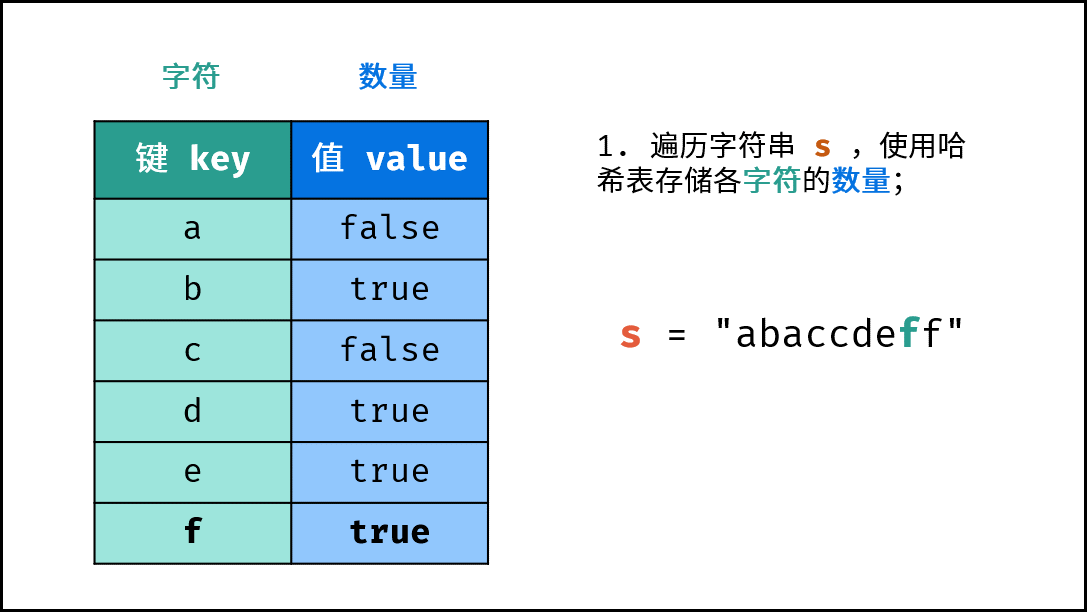
- 遍历字符串
arr,使用哈希表统计 “各字符数量是否> 1”。 - 再遍历字符串
arr,在哈希表中找到首个 “数量为1的字符”,并返回。
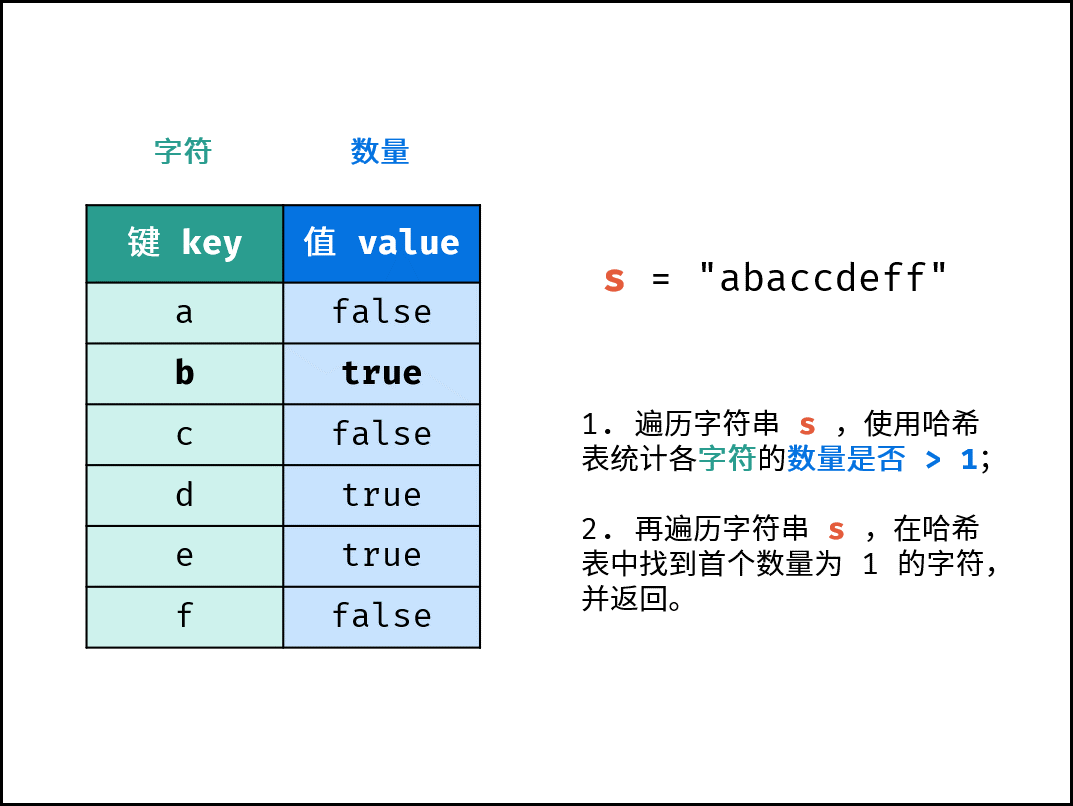 {:align=center width=450}
{:align=center width=450}
算法流程:
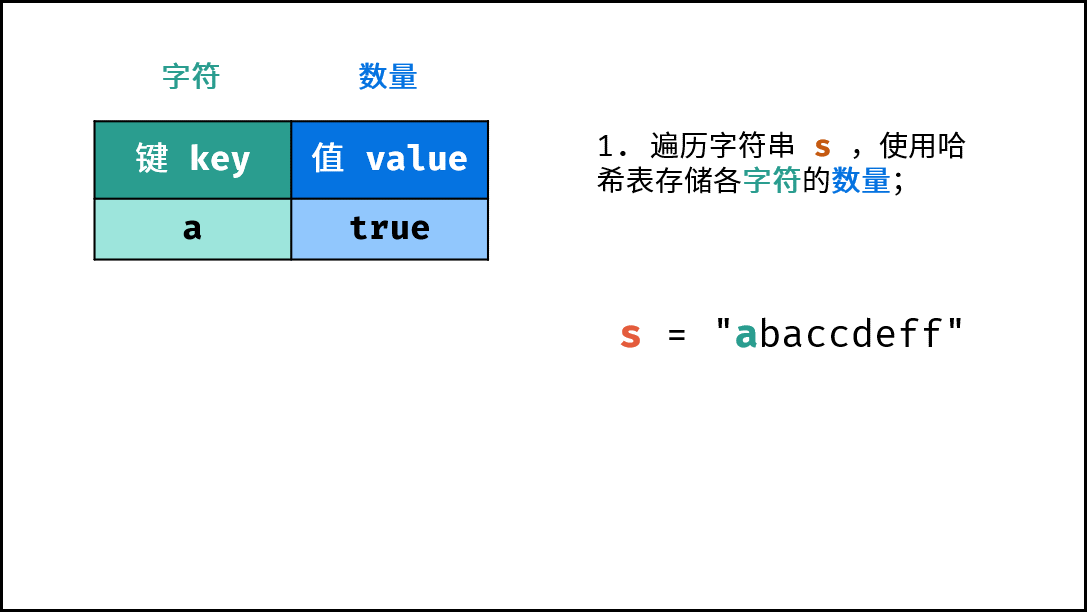
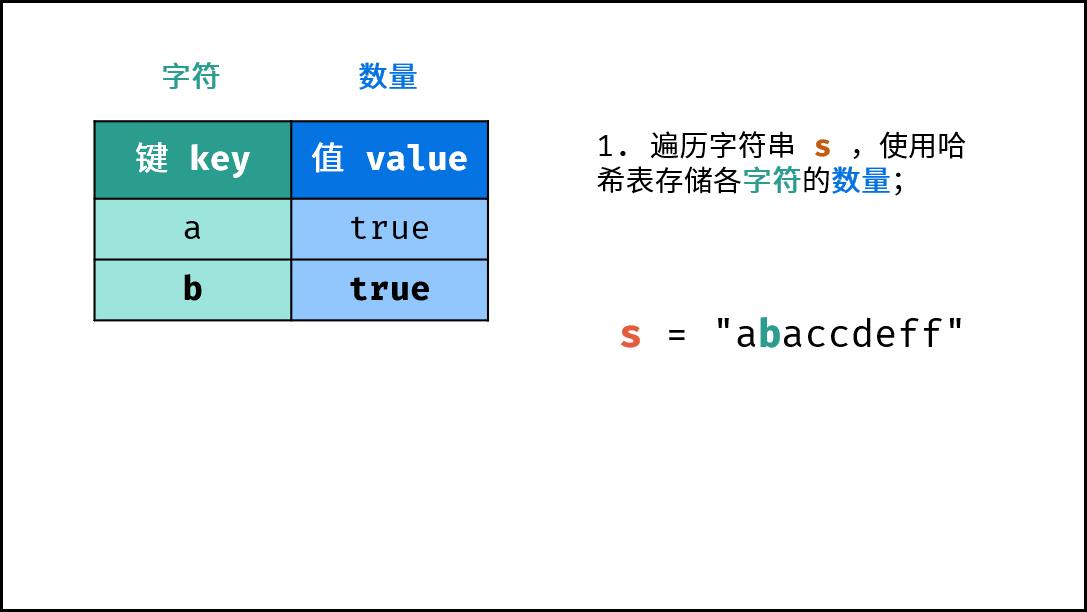
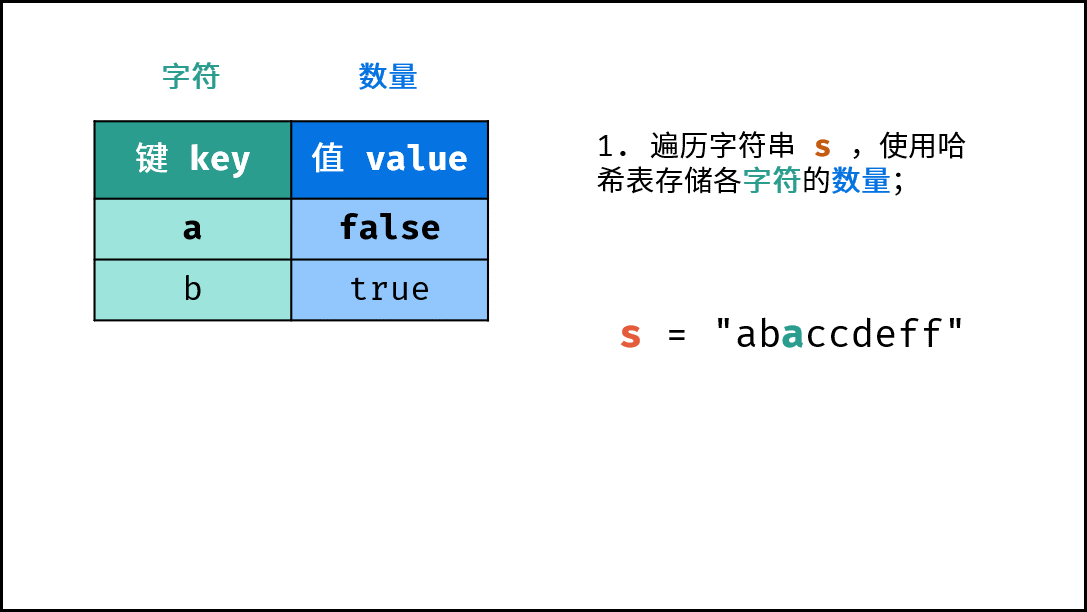
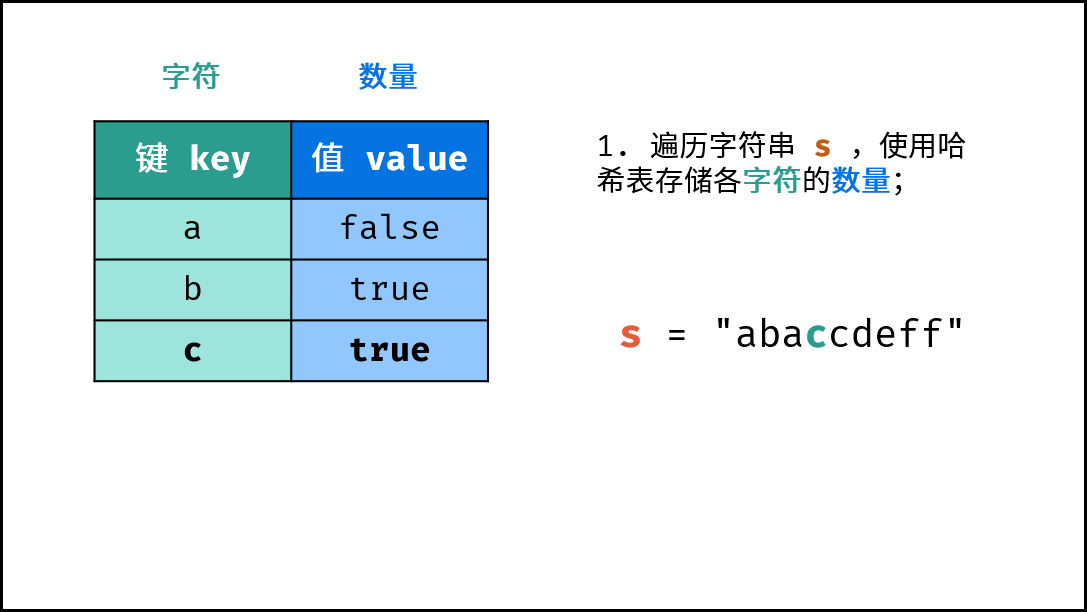
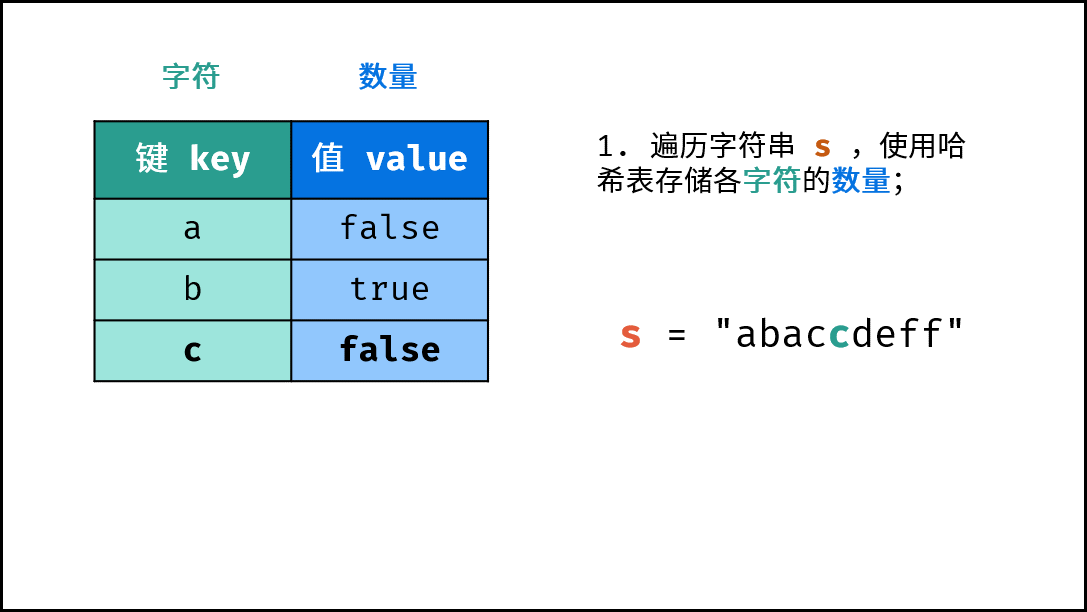
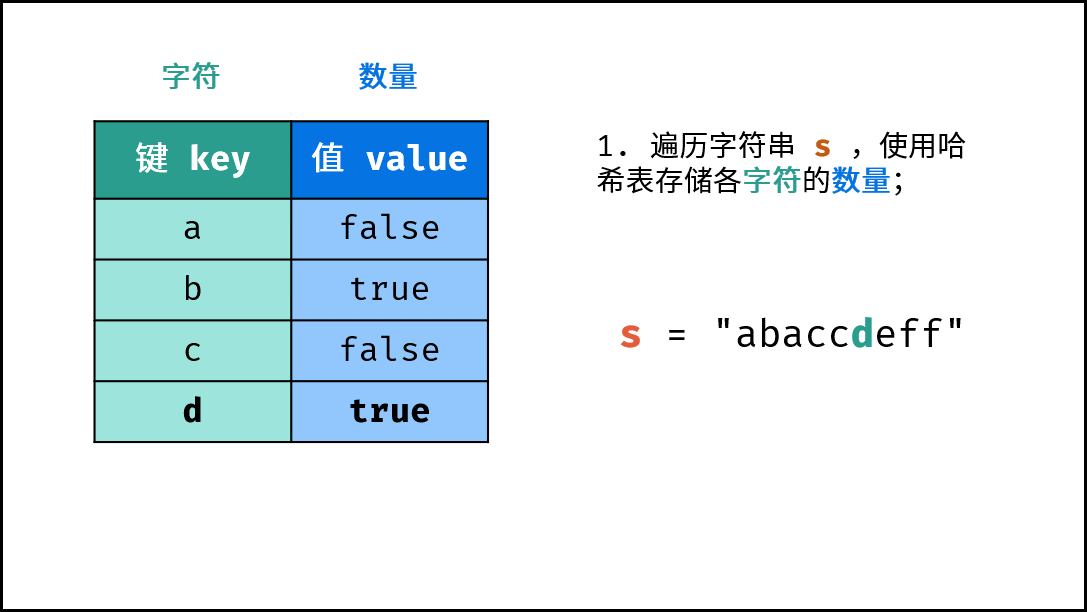
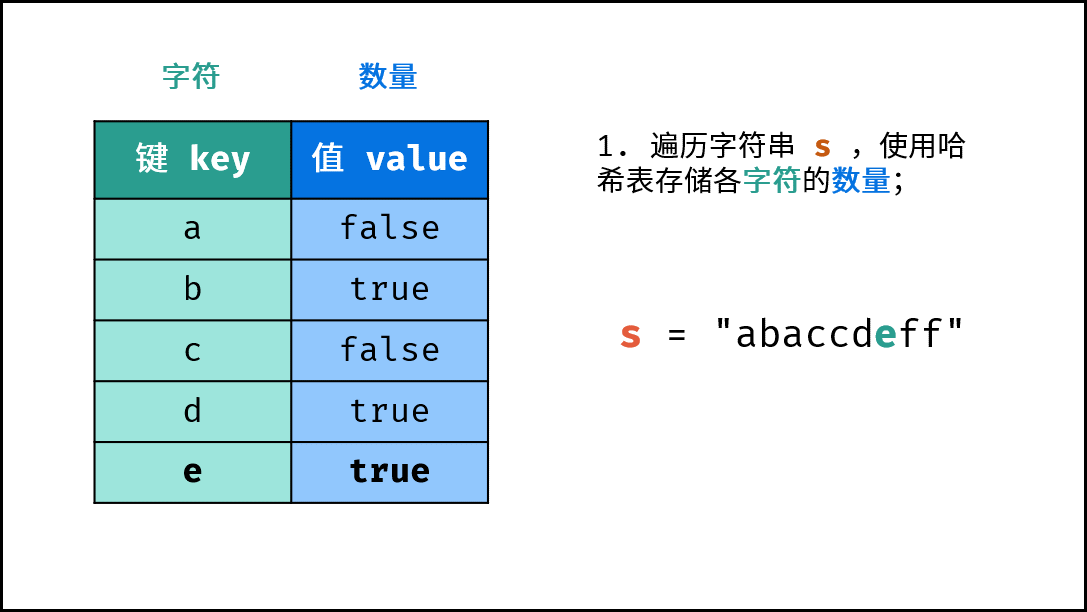
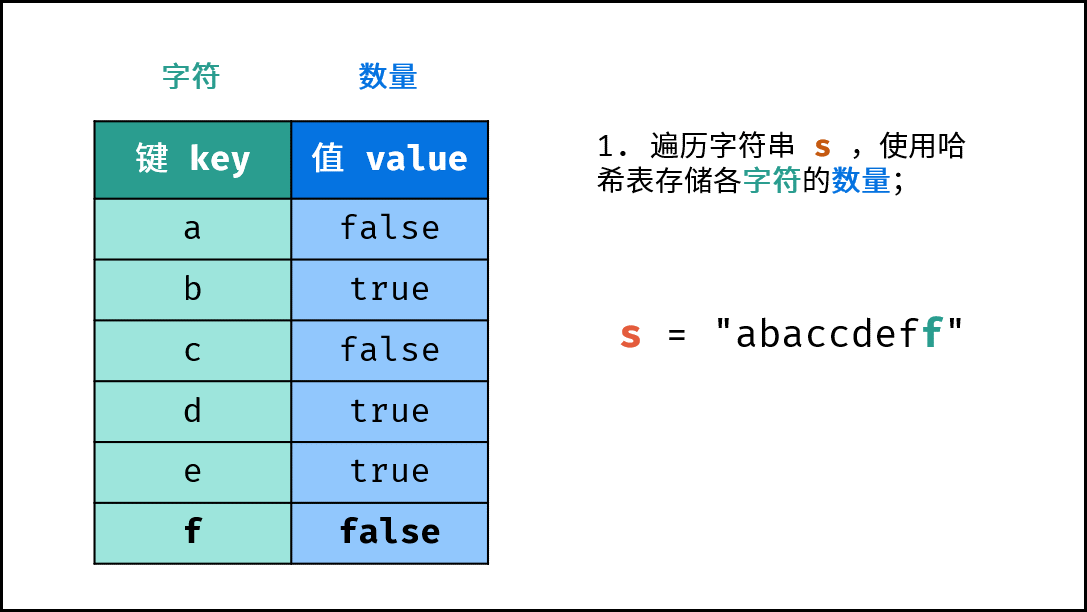
- 初始化: 字典 (Python)、HashMap(Java)、map(C++),记为
hmap; - 字符统计: 遍历字符串
arr中的每个字符c;- 若
hmap中 不包含 键(key)c:则向hmap中添加键值对(c, True),代表字符c的数量为1; - 若
hmap中 包含 键(key)c:则修改键c的键值对为(c, False),代表字符c的数量> 1。
- 若
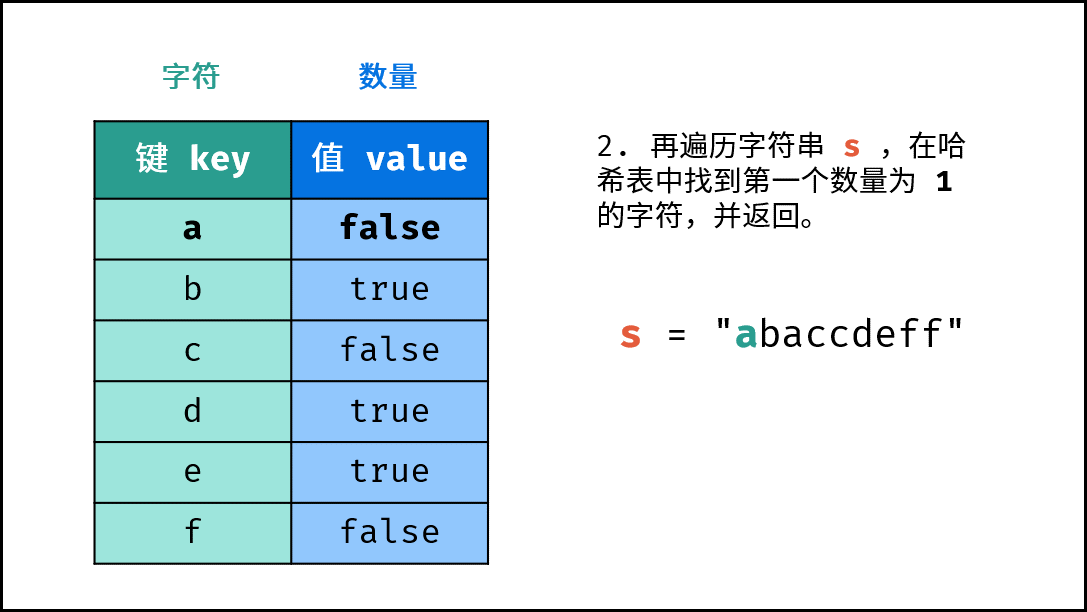
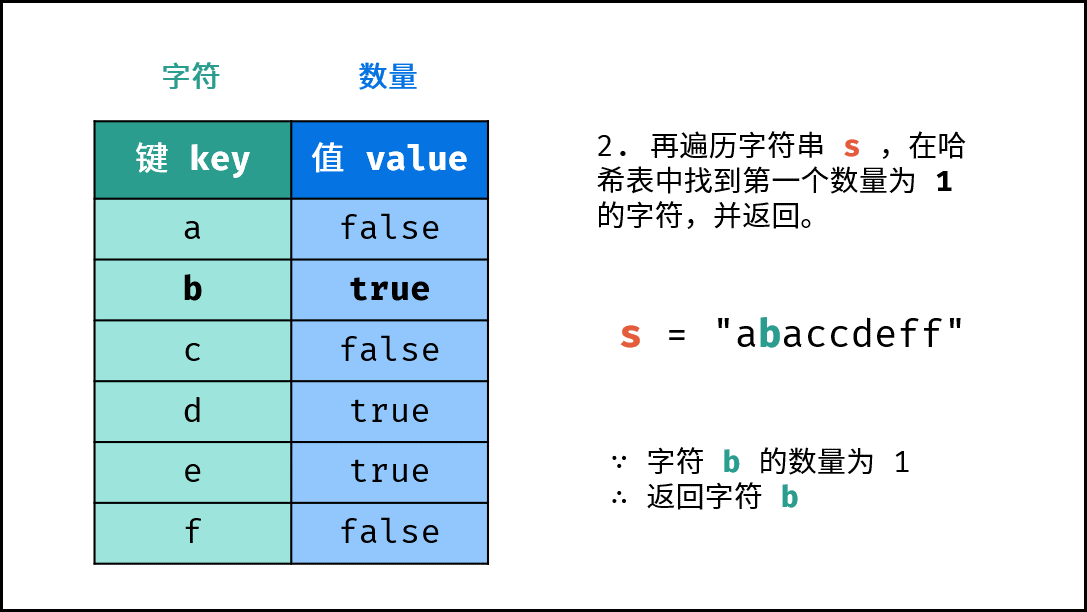
- 查找数量为
1的字符: 遍历字符串arr中的每个字符c;- 若
hmap中键c对应的值为True:,则返回c。
- 若
- 返回
' ',代表字符串无数量为1的字符。
下图中的
s对应本题的arr。
< ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, >
>
代码:
Python 代码中的 not c in hmap 整体为一个布尔值;c in hmap 为判断字典中是否含有键 c 。
class Solution:
def dismantlingAction(self, arr: str) -> str:
hmap = {}
for c in arr:
hmap[c] = not c in hmap
for c in arr:
if hmap[c]: return c
return ' '
class Solution {
public char dismantlingAction(String arr) {
HashMap<Character, Boolean> hmap = new HashMap<>();
char[] sc = arr.toCharArray();
for(char c : sc)
hmap.put(c, !hmap.containsKey(c));
for(char c : sc)
if(hmap.get(c)) return c;
return ' ';
}
}
class Solution {
public:
char dismantlingAction(string arr) {
unordered_map<char, bool> hmap;
for(char c : arr)
hmap[c] = hmap.find(c) == hmap.end();
for(char c : arr)
if(hmap[c]) return c;
return ' ';
}
};
复杂度分析:
- 时间复杂度
O(N):N为字符串arr的长度;需遍历arr两轮,使用O(N);HashMap 查找操作的复杂度为O(1); - 空间复杂度
O(1): 由于题目指出arr只包含小写字母,因此最多有 26 个不同字符,HashMap 存储需占用O(26) = O(1)的额外空间。
方法二:有序哈希表
在哈希表的基础上,有序哈希表中的键值对是 按照插入顺序排序 的。基于此,可通过遍历有序哈希表,实现搜索首个 “数量为 1 的字符”。
哈希表是 去重 的,即哈希表中键值对数量 \leq 字符串 arr 的长度。因此,相比于方法一,方法二减少了第二轮遍历的循环次数。当字符串很长(重复字符很多)时,方法二则效率更高。
代码:
Python 3.6 后,默认字典就是有序的,因此无需使用 OrderedDict() ,详情可见:为什么Python 3.6以后字典有序并且效率更高?
Java 使用 LinkedHashMap 实现有序哈希表。
由于 C++ 未提供自带的链式哈希表,因此借助一个 vector 按序存储哈希表 hmap 中的 key ,第二轮遍历此 vector 即可。
class Solution:
def dismantlingAction(self, arr: str) -> str:
hmap = collections.OrderedDict()
for c in arr:
hmap[c] = not c in hmap
for k, v in hmap.items():
if v: return k
return ' '
class Solution:
def dismantlingAction(self, arr: str) -> str:
hmap = {}
for c in arr:
hmap[c] = not c in hmap
for k, v in hmap.items():
if v: return k
return ' '
class Solution {
public char dismantlingAction(String arr) {
Map<Character, Boolean> hmap = new LinkedHashMap<>();
char[] sc = arr.toCharArray();
for(char c : sc)
hmap.put(c, !hmap.containsKey(c));
for(Map.Entry<Character, Boolean> d : hmap.entrySet()){
if(d.getValue()) return d.getKey();
}
return ' ';
}
}
class Solution {
public:
char dismantlingAction(string arr) {
vector<char> keys;
unordered_map<char, bool> hmap;
for(char c : arr) {
if(hmap.find(c) == hmap.end())
keys.push_back(c);
hmap[c] = hmap.find(c) == hmap.end();
}
for(char c : keys) {
if(hmap[c]) return c;
}
return ' ';
}
};
复杂度分析:
时间和空间复杂度均与 “方法一” 相同,而具体分析:方法一 需遍历 arr 两轮;方法二 遍历 arr 一轮,遍历 hmap 一轮( hmap 的长度不大于 26 )。